在 PDF 翻译里,真正难的通常不是翻译本身,而是翻译后是否还能按人类阅读顺序读下去。
很多失败结果都卡在这个问题上:多栏乱序、图注错位、脚注插队、段落断裂。
我们最终落地的流程分三步:
- PDF 转成易解析中间格式
- 按阅读链做整段翻译
- 回写版面并导出 PDF

1)为什么要先转中间格式?
PDF 是视觉排版容器,不是天然语义文档。
如果直接逐行抽取后翻译,最容易丢上下文和结构关系。
所以我们会先把结构信息固化到中间格式,至少包含:
- 坐标与页内位置
- 段落和层级归属
- 阅读顺序索引
- 标题/正文/图注/脚注标签
先把结构稳住,再翻译,后续回写才不会散。
2)为什么用整段翻译而不是逐行翻译?
逐行翻译最常见的问题是语义断裂,学术和技术文档会更明显。
我们的做法是:
- 先按阅读链合并为段
- 以段为最小翻译单元
- 保留编号、锚点和不可译片段
- 翻译后再映射回原结构
这样做的直接收益是:读起来更连贯,术语一致性更好,返工更少。
3)阅读顺序怎么保证不乱?
阅读顺序不是顺便处理,而是单独建模。
我们会在中间格式中维护阅读链规则:
- 列内优先
- 主文优先
- 图注邻接
- 脚注后置
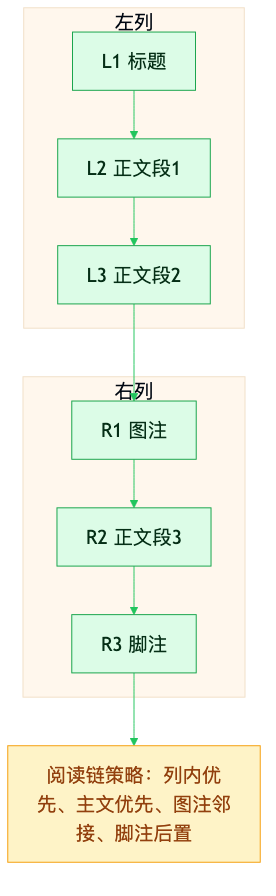
这一步决定了译文最终是否像一篇能读的文档。
4)回写 PDF 时重点看什么?
回写不是替换文本这么简单,而是要保证可交付。
重点包括:
- 段落层级保持
- 编号与锚点保留
- 图表邻接关系稳定
- 译文变长后的换行与溢出自适应

最终目标很明确:不是翻得出来,而是拿去就能用。
适用场景
- 学术论文(多栏、脚注、图注)
- 技术白皮书(图文混排)
- 行业报告(结构复杂、交付要求高)
如果你现在遇到的是“能翻,但不可读、不可交付”,问题通常不在模型本身,而在处理链路设计。
能力边界与限制
- 超复杂版式仍建议预留人工抽检时间
- 图表和脚注密集文档建议先抽样验证顺序
- 大批量交付建议先跑小样,确认稳定后再全量执行